
【上流SE必見】一歩先にいくデータベース設計の実践テクニック


本記事では、上流工程に携わるエンジニアが知っておきたいデータベース設計の実践ノウハウについてまとめました。
データベース設計には正解がなく、業務要件とさまざまなトレードオフを勘案して平衡点を見つけ出していく必要があります。
そのため、経験を積まないと習得が難しいとされているデータベース設計ですが、
「データベースに起因して、コードが歪つになっている」
「新規プロダクトの設計やレガシー化システムの改修を任されたが、設計力に自信がない」
といったお悩みをお持ちの方に、ご参考にしていただければ幸いです。
データベース設計を学ぶメリット
クラウド、ビッグデータ、AIなどの技術トレンドを背景に、取り扱うデータ量が加速度的に増え、データ活用の形も多様化しています。
こうしたデータ中心の時代では、いかにしてデータを整合的に保存し、必要な情報を迅速に取り出せるようにするかが鍵となります。
システムの設計手法は、DOA(Data Oriented Approach:データ中心アプローチ)が基本であり、データベースがコードの品質を左右するといっても過言ではありません。
適切にデータベース設計をおこなうことで、アプリケーションの性能向上をもたらすほか、将来の開発作業における保守性を担保することができます。
データモデリングの基礎知識
データモデリングとは、データベースによるデータ管理が出来るよう、実世界の情報を抽象化し、体系的に表現する作業です。
データモデルとして俯瞰的にビジネス活動をとらえて可視化することで、組織内での認識の齟齬を防ぎ、システム設計に一貫性をもたらします。
管理対象として抽出するデータの集合体のことを「エンティティ」(実体)、エンティティが有する属性情報を「アトリビュート」、エンティティ同士の依存関係を「リレーションシップ」と呼びます。
なお、データモデリングで登場するエンティティ、アトリビュート、リレーションシップは、最終的なデータベースではそれぞれテーブル、カラム、外部キーに変換されます。
データモデリングの流れ
データモデリングは一般的に、概念設計、論理設計、物理設計という3つのステップを通しておこないます。
それぞれのフェーズのアウトプットとして概念モデル、論理モデル、物理モデルが作成されます。
概念設計
概念設計とは、実世界に存在するさまざまなデータ情報から、何を、どういったフォーマットで保存するかを決めるプロセスです。
このプロセスでは実装手段は考慮せず、理想的なデータのあるべき姿を模索します。
エンティティの抽出
はじめに、データそのものであるエンティティの抽出をおこないます。
エンティティは、大きく「リソース系」と「イベント系」の2種類に分類できます。
リソース系エンティティとは人、モノ、組織、金、時間といった企業の経営資源であり、名詞で抜き出せるという特徴があります。
一方、イベント系エンティティとは、企業活動のアクティビティにより発生する出来事の履歴であり、「〜する」を付けて成り立つ場合が多いです。(販売する、出荷する、調達するetc…)
エンティティ抽出におけるキーポイント
次にエンティティ抽出において、注意したい項目を4つご紹介します。
1つ目は、イベント系エンティティの素性(5W2H)のリストアップです。
たとえば、スクール経営での月謝請求というイベント系エンティティを補足した場合には、次のように属性や関連するエンティティの候補を考えていきます。
- Who(誰が)・・・スクール運営者
- Whom(誰に)・・・会員
- When(いつ)・・・請求日時
- What(何を)・・・月謝
- Where(どこで)・・・教室
- How(どのように)・・・請求方法
- How much(いくら)・・・月謝金額
who、whom、what、whereに当たるデータはリソース系エンティティの候補となり、when、how、how muchに当たるデータはアトリビュートの候補となります。
このように、出来事の要素を分解することによって過不足を補うことができます。
2つ目は、さまざまなユースケースについてシミュレーションをおこなうことです。
特に見落とされがちなのが、イレギュラーケースへの対応です。
業務のメインフローだけでなく、起こりうるケースを隈なく想定しておくことで仕様漏れや誤りの防止に繋がるでしょう。
3つ目は、経営戦略や将来ビジョンの把握です。
システム稼働後のデータモデル変更は容易でなく、改修作業に多大なコストを要します。
そのため、ビジネスの目指すべきところから将来の仕様変更を予見しておき、変更を吸収しうる設計にしておくことがシステム寿命を延ばすコツとなります。
そして4つ目は、ビジネスの文脈で必要なアウトプットを入念に検討することです。
入金額が超過している場合に、超過分を返金するというケースを例に考えてみます。
「返金」を請求データの状態遷移と捉え、アトリビュートの一つとして設計するといくつかの問題が生じます。
いつ返金をしたかという情報が欠落しているほか、過去に遡って状態を参照するといった挙動ができなくなってしまいます。(*業務要件次第であり、必ずしもこの設計が誤りという訳ではありません。)
円滑に業務をおこなう上で参照すべきデータが取得できるかという観点でレビューをおこない、ライフサイクルが重要となる出来事についてはイベント系エンティティとして切り出すことが求められます。
リレーションシップ
エンティティのうち、他のエンティティに依存せず存在するものを強実体、他のエンティティが存在しなくなると自身のエンティティもなくなるものを弱実体と言います。
概念モデルを作成する際に、両者を区分して関連を表現することで、エンティティ同士のリレーションシップが把握しやすくなります。
また、多対多のリレーションシップは非正規形となり、論理モデルとして好ましくないため、両者の間のリレーションシップをエンティティとして捉え(連関エンティティと言います)、多対多を排除しておきます。
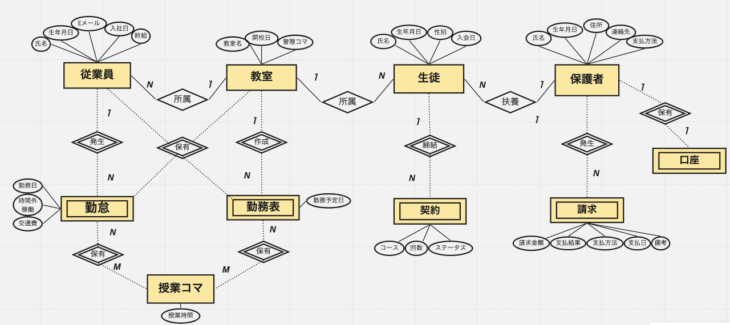
概念モデルの例
後工程で作成するER図のフォーマットに合わせ、エンティティは四角形のボックス、リレーションシップはエンティティ同士を結ぶ実線で作成しています。
論理設計
論理設計は、概念設計のアウトプットである概念モデルをさらに具体化し、リレーショナルデータベースに基づいて正規化されたモデルに変換するプロセスです。
このプロセスにおいても概念設計と同様、技術には依存せずデータのあるべき姿を検討します。
正規化とは
正規化とはわかりやすく言うと、テーブル(二次元表)から縦軸、横軸の繰り返し項目を取り除き、異なるレベルのエンティティをテーブルレベルで分離させる作業になります。
正規化がもたらすメリットとしては、冗長性の排除により、更新時の不整合を防止できる点、テーブルの持つ意味が明確になり開発者が理解しやすい点などがあげられます。
第1正規化
第1正規化とは非正規形のテーブル(二次元表)における繰り返しの項目を取り除き、全ての値をスカラ値(単一の値)にするという、正規化の第一段階作業を指します。
第2正規化
「A列の値が決まればB列の値が一つに決まる」という関係を関数従属性と呼びます。
第2正規化は主キーの列に対する関数従属(「部分関数従属」と言います)を解消し、冗長性を排除する作業です。
関数従属を解消する手段は、テーブルの分割であり、部分関数従属の関係にある列とその従属列を独立したテーブルとして切り出すことによって第2正規形を得られます。
第3正規化
第3正規化とは、第2正規形からさらに主キー以外の列に対する関数従属(推移的関数従属と言います)を解消する作業を指します。
この結果、いずれのテーブルもすべての属性が主キーに対して完全関数従属であるテーブルとなります。
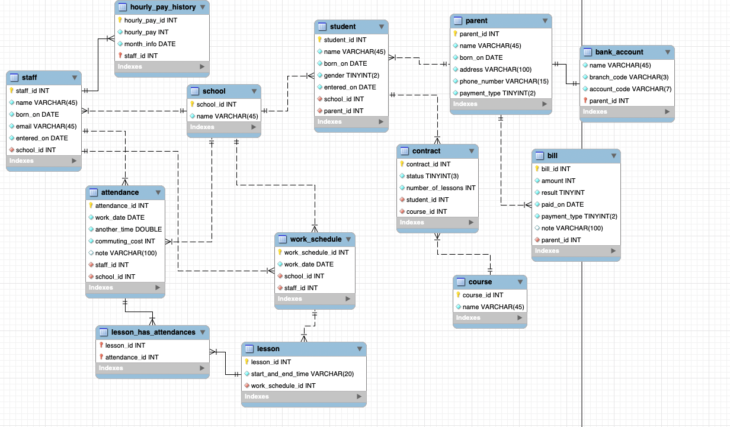
ER図
論理モデルにはER図を用います。
ER図(Entity Relationship Diagram)は、実体関連モデルと呼ばれ、各エンティティ(テーブル)の役割や相互の関連を効率的に把握できるよう図式化したものです。
実務では何百という数のテーブルが作られることも珍しくなく、大規模なシステムのデータ間の処理構造をシンプルに表現する手法として、開発において必須級のドキュメントとなっています。
ER図では、テーブル同士の関連を細分化し、カーディナリティ(多重度)と呼ばれる記号で1対1、1対多、多対多の関係を表現します。
物理設計
物理設計ではデータサイズの観点から物理的なデータ配置を決定するとともに、パフォーマンスを考慮してデータベース構造を整理し、より現実的なレベルの物理モデルとして詰めていきます。
データサイズについては、初期データ量や年間の増加量の見積もりが必要となります。
新規サービスなどで予測を立てるのが困難な場合には、容量にある程度余裕を持たせるか、柔軟にストレージを追加ができる構成をとると良いでしょう。
パフォーマンスについては、レスポンスタイム、スループット、リソース使用率などの指標を用いて、性能要件を具体的に決めていきます。
レスポンスタイムは処理実行指示を与えてから応答を得るまでの時間、スループットは単位時間あたりに処理できるデータ量、リソース使用率は単位時間内にどれだけのリソースを使用するかを表し、平常時とピーク時の2つを考慮するのが基本の考え方となります。
以上を元にサーバーのCPU、メモリ、ストレージのI/Oなどのスペックを決定していきます。
また、データベースの整合性(正規化)とパフォーマンスは、強いトレードオフの関係にあるため、時と場合によっては、正規化を崩す選択も必要となります。
とはいえ、正規化は可能な限り高次にすることが原則であり、基本的には正規化を優先し、その後にパフォーマンスなどの現実問題に対して折り合いをつけていくフローが望ましいと考えられます。
データベースの種類
業務システムのデータベースにおいてデファクトスタンダードともいえるRDBMS(リレーショナル型データベース)ですが、昨今では、非リレーショナル型であるNoSQLの利用が広がりつつあります。
NoSQLとは、一般に “Not only SQL” と解釈され、RDBMS以外のデータベースシステム全般を指します。
敢えて正規化を崩し単純なデータ構造を採用することで、パフォーマンスの向上や容易なスケールアウトを実現を可能としています。
RDBMSとNoSQLの比較
では、それぞれのメリット・デメリットについて見ていきます。
RDBMSは厳格に設計できる仕組みとなっており、複雑なデータ構造であっても整合性や一貫性を保つことができます。
また、SQLによりテーブル同士を結合して検索するなど複雑な操作が可能となります。
一方で、分散性・拡張性・処理速度の面ではデメリットがあります。
まず分散性ですが、別サーバーにテーブルを分けてしまうと書き込み時の一貫性を保持できず、原則として1台のサーバーで管理することとなります。
次に拡張性ですが、RDBMSはデータ構造を予め定義する必要があるため、拡張させるには技術的側面からコストがかかります。
最後に処理速度ですが、分散しての並列処理をおこなうことができないため、データが肥大化するほど処理速度が遅くなってしまうというデメリットがあります。
対してNoSQLの最大のメリットは、高速な処理速度にあります。
RDBMSでは、取り扱いが難しいビックデータやクラウドなどの大容量データでも、シンプルなデータ構造や水平分散を駆使することで、全体の処理速度を担保できます。
一方、NoSQLはデータの一貫性が保証されていないため、同時実行制御が必要な更新や削除処理が頻発すると、データの整合性を担保できない場合があります。
また、SQLの使用ができないために検索能力が低いというデメリットがあります。
最後に
いかがでしたでしょうか。
データベース設計に統一的な答えはなく、業務要件とさまざまなトレードオフを勘案して平衡点を見つけ出していく必要があります。
適切な設計をおこなうに当たっては、その前段階として要件を明確にすることが欠かせません。

では要件定義のポイントについて解説していますのでよろしければこちらもご覧ください。
またクランチタイマーでは、フルリモートで一緒に働くエンジニアを募集中です。
詳細は、以下のWantedlyページをご確認ください。
この記事をシェア

最新情報を確認する

CONTACT
お気軽にお問い合わせください。
TEL082-299-2286
NEWSLETTER
代表の佐々⽊が⽉に1回お届けするメールマガジン。
国内外スタートアップの最新情報や最新技術のサマリー、クランチタイマーの開発事例紹介など、ITに関する役⽴つ情報を中⼼にお送りします!